
What is Latency ?| Definition of the Concept of Network Latency
In our digitally dominated world, the term ‘latency’ is frequently mentioned in discussions about internet speed and network performance....


What is Latency ?| Definition of the Concept of Network Latency

How to Monitor Network Speed: Become the Master of Your Bandwidth in 2024!

Reduce Latency: 7 Proven Strategies for Efficient Operations

Shopping for latency?

5G environmental and social impacts? – part 2

5G environmental and social impacts? – part 1

Industrial use cases requiring 5G ultra-low latency
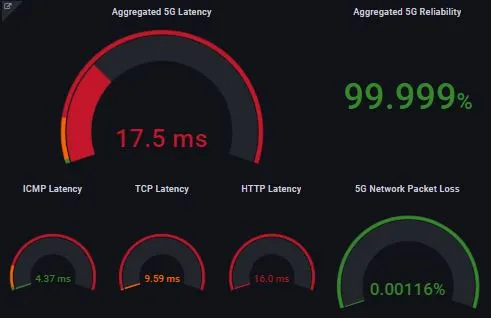
Ultra-Low Latency is the real disruption of 5G networks